



혹시 AI 모델 학습 속도 때문에 밤샘 작업하신 적 있으신가요? 😭 답답한 마음 저도 너무 잘 알아요! 😫 하지만 이제 걱정 마세요! GPU를 활용하면 마치 슈퍼카 엔진을 장착한 듯 엄청난 속도 향상을 경험할 수 있거든요! 🏎️ 이 글을 통해 GPU for AI 활용법을 마스터하고, 남들보다 빠르게 AI 개발 능력을 업그레이드 해보세요! 😉 지금 바로 시작해볼까요?
✨ 핵심 요약 (3가지) ✨
- GPU 아키텍처 & CUDA 프로그래밍: AI 연산에 최적화된 GPU 구조와 병렬 처리 능력을 극대화하는 CUDA 프로그래밍 기초를 다져보세요!
- PyTorch/TensorFlow 활용: 딥러닝 프레임워크와 GPU의 환상적인 조합! 모델 학습 효율을 높이는 핵심 비법을 알아볼까요?
- 최적화 & 확장 학습: 데이터 병목 현상 해결, 프로파일링 도구 활용, 분산 학습 환경 구축까지! GPU 활용의 A to Z를 정복해봐요!
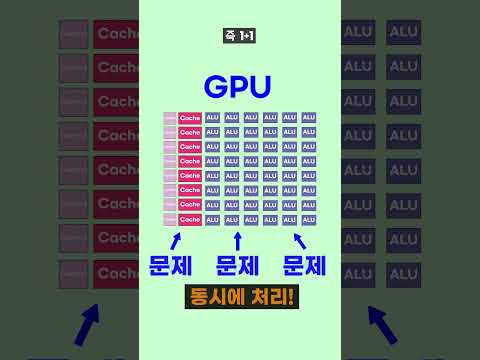
GPU, 왜 AI에 필수일까요? 🤔
GPU(Graphics Processing Unit)는 원래 그래픽 처리를 위해 설계되었지만, AI, 특히 딥러닝 분야에서 엄청난 잠재력을 보여주고 있어요. CPU와 달리 수천 개의 코어를 가지고 있어서 병렬 연산에 특화되어 있거든요. 마치 여러 명의 요리사가 동시에 요리하는 것처럼, GPU는 대규모 데이터를 동시에 처리할 수 있어서 AI 모델 학습 속도를 획기적으로 향상시켜 줍니다. 🧑🍳👩🍳👨🍳
딥러닝 모델은 엄청난 양의 데이터를 가지고 학습해야 하는데, CPU만으로는 너무 많은 시간이 걸려요. 하지만 GPU를 사용하면 수십 배, 심지어 수백 배까지 학습 속도를 높일 수 있다는 사실! 🚀 시간을 금처럼 여기는 AI 개발자에게 GPU는 선택이 아닌 필수랍니다! ✨
GPU 아키텍처, 핵심만 쏙쏙! 🤓
GPU는 SIMD(Single Instruction, Multiple Data) 아키텍처를 기반으로 동작해요. 하나의 명령어로 여러 데이터를 동시에 처리하는 방식이죠. 마치 컨베이어 벨트처럼 데이터가 쫙쫙 처리되는 모습을 상상해보세요! 🏭
GPU 아키텍처를 이해하는 것은 GPU 성능을 최대한 활용하는 데 매우 중요해요. 예를 들어, NVIDIA의 GPU는 스트리밍 멀티프로세서(SM)라는 핵심 구성 요소로 이루어져 있는데, 각 SM은 여러 개의 코어를 가지고 있어서 병렬 연산을 수행합니다. AMD의 GPU도 비슷한 구조를 가지고 있어요.
| GPU 제조사 | 주요 아키텍처 | 특징 |
|---|---|---|
| NVIDIA | Ampere, Ada Lovelace | Tensor Core를 통한 텐서 연산 가속, Ray Tracing 지원으로 고품질 그래픽 구현 |
| AMD | RDNA, CDNA | 경쟁력 있는 가격, 뛰어난 전성비, OpenCL 지원 |
CUDA 프로그래밍, GPU 성능 200% 활용! 💪
CUDA(Compute Unified Device Architecture)는 NVIDIA에서 개발한 병렬 컴퓨팅 플랫폼 및 프로그래밍 모델이에요. CUDA를 사용하면 C, C++, Python 등의 언어를 사용하여 GPU를 프로그래밍할 수 있습니다. 마치 GPU에게 직접 명령을 내리는 것과 같다고 생각하면 돼요! 🗣️
CUDA 프로그래밍의 핵심은 스레드, 블록, 그리드라는 개념을 이해하고 활용하는 것입니다. 스레드는 GPU에서 실행되는 가장 작은 실행 단위이고, 블록은 여러 개의 스레드로 구성되며, 그리드는 여러 개의 블록으로 구성됩니다. 이러한 계층 구조를 통해 GPU는 대규모 병렬 연산을 효율적으로 수행할 수 있어요.
하지만 CUDA 프로그래밍은 CPU 프로그래밍과는 다른 몇 가지 주의사항이 있어요. 예를 들어, GPU 메모리 관리는 CPU 메모리 관리보다 더 복잡하고, 데이터 전송 오버헤드를 최소화하는 것이 중요합니다.
PyTorch & TensorFlow, 딥러닝 프레임워크와 GPU의 찰떡궁합! 💖

PyTorch와 TensorFlow는 가장 널리 사용되는 딥러닝 프레임워크입니다. 이 프레임워크들은 GPU를 완벽하게 지원하며, GPU를 사용하여 모델 학습을 가속화할 수 있는 다양한 기능을 제공해요. 마치 전문 요리 도구를 사용하는 것처럼, PyTorch와 TensorFlow는 AI 개발을 더욱 쉽고 효율적으로 만들어줍니다. 🍳
PyTorch와 TensorFlow는 GPU를 자동으로 감지하고 활용하며, 사용자는 간단한 코드 몇 줄만으로 GPU를 사용하여 모델을 학습할 수 있습니다. 예를 들어, PyTorch에서는 .to('cuda') 함수를 사용하여 모델과 데이터를 GPU로 옮길 수 있고, TensorFlow에서는 tf.device('/GPU:0') 컨텍스트 매니저를 사용하여 GPU에서 연산을 수행할 수 있습니다.
# PyTorch 예시
model = MyModel().to('cuda')
data = data.to('cuda')
output = model(data)
# TensorFlow 예시
with tf.device('/GPU:0'):
output = model(data)데이터 병목 현상, 해결 없이는 성능 향상도 없다! 🚧
GPU를 아무리 좋은 걸 써도, 데이터가 제때 공급되지 않으면 성능이 제대로 나오지 않아요. 마치 슈퍼카에 자전거 바퀴를 달고 달리는 것과 같죠! 🚴♀️ 데이터 병목 현상은 GPU 활용 시 가장 흔하게 발생하는 문제 중 하나입니다.
데이터 병목 현상을 해결하는 방법은 여러 가지가 있습니다.
- 데이터 로딩 속도 향상: 더 빠른 저장 장치(SSD, NVMe SSD)를 사용하거나, 데이터 로딩 파이프라인을 최적화하여 데이터 로딩 속도를 향상시킬 수 있습니다.
- 데이터 전처리 최적화: 데이터 전처리 과정을 GPU에서 수행하거나, 배치 크기를 조정하여 데이터 전처리 시간을 단축할 수 있습니다.
- 데이터 증강 활용: 데이터 증강을 통해 데이터셋 크기를 늘리고, 모델의 일반화 성능을 향상시킬 수 있습니다.
최적화 수준별 효과 비교, 얼마나 달라질까? 📈

GPU 최적화 수준에 따라 모델 학습 속도와 메모리 사용량이 크게 달라질 수 있어요. 마치 옷을 맞춤으로 입는 것처럼, AI 모델에 맞는 최적화 방법을 찾아야 합니다.
| 최적화 수준 | 효과 | 고려사항 |
|---|---|---|
| 기본 | GPU 기본 성능 활용, 간단한 코드 수정만으로 성능 향상 가능 | 데이터 병목 현상 발생 가능성 높음 |
| 중간 | 데이터 로딩 및 전처리 최적화, 배치 크기 조정 | 코드 복잡도 증가, 최적 배치 크기 탐색 필요 |
| 고급 | 모델 구조 최적화, 양자화, 가지치기 등 고급 기술 적용 | 높은 수준의 전문 지식 필요, 모델 정확도 감소 가능성 고려 |
코드 복잡도 증가, 감당할 수 있겠어? 🤯
GPU 최적화는 성능 향상을 가져다주지만, 코드 복잡도를 증가시킬 수 있다는 단점이 있어요. 마치 복잡한 레시피를 따라 요리하는 것처럼, GPU 최적화는 더 많은 노력과 전문 지식을 필요로 합니다. 🍳
CUDA 프로그래밍은 CPU 프로그래밍보다 더 복잡하고, 디버깅도 더 어려울 수 있습니다. 또한, PyTorch와 TensorFlow의 고급 기능을 사용하려면 프레임워크에 대한 깊이 있는 이해가 필요합니다.
하지만 걱정 마세요! 🤗 꾸준히 학습하고 경험을 쌓으면 GPU 최적화의 달인이 될 수 있습니다! 🧑🎓
프로파일링 도구 사용, 숨겨진 병목 지점을 찾아라! 🕵️♀️
프로파일링 도구는 GPU 성능 분석에 필수적인 도구입니다. 마치 의사가 환자를 진찰하는 것처럼, 프로파일링 도구를 사용하여 GPU 사용량, 메모리 사용량, 연산 시간 등을 분석하고, 병목 지점을 찾아낼 수 있습니다. 🩺
NVIDIA Nsight Systems, NVIDIA Nsight Compute, PyTorch Profiler, TensorFlow Profiler 등 다양한 프로파일링 도구가 있습니다. 이러한 도구를 사용하면 GPU 성능을 정확하게 측정하고, 최적화 방향을 설정할 수 있습니다.
분산 학습 환경 구축, 더 빠르게, 더 크게! 🚀
단일 GPU로는 감당하기 힘든 대규모 모델 학습에는 분산 학습 환경 구축이 필수적입니다. 마치 여러 대의 컴퓨터를 연결하여 하나의 슈퍼컴퓨터를 만드는 것과 같아요! 💻 💻 💻
분산 학습은 데이터 병렬 처리, 모델 병렬 처리 등 다양한 방식으로 구현할 수 있습니다. 데이터 병렬 처리는 데이터를 여러 GPU에 나누어 학습하는 방식이고, 모델 병렬 처리는 모델을 여러 GPU에 나누어 학습하는 방식입니다.
PyTorch, TensorFlow는 분산 학습을 지원하는 다양한 기능을 제공하며, Horovod, DeepSpeed 등 분산 학습을 위한 라이브러리도 있습니다.
양자화 & 가지치기, 모델 크기는 줄이고, 성능은 그대로! ✂️
양자화와 가지치기는 모델 크기를 줄이고, 추론 속도를 향상시키는 기술입니다. 마치 다이어트를 통해 몸무게를 줄이는 것처럼, 양자화와 가지치기는 모델을 더욱 가볍고 효율적으로 만들어줍니다. 🏋️♀️
양자화는 모델의 가중치와 활성화를 낮은 정밀도로 표현하는 방식이고, 가지치기는 모델의 중요하지 않은 연결을 제거하는 방식입니다. 이러한 기술을 사용하면 모델 크기를 크게 줄일 수 있으며, 메모리 사용량과 전력 소비를 줄일 수 있습니다.
후기/사례: GPU, AI 개발의 게임 체인저! 🏆
GPU는 AI 개발 분야에서 혁명적인 변화를 가져왔습니다. 이전에는 상상할 수 없었던 복잡한 모델을 학습하고, 현실적인 수준의 성능을 달성할 수 있게 되었죠. 마치 마법 지팡이처럼, GPU는 AI 개발자들에게 무한한 가능성을 열어주었습니다. 🧙♂️
실제로 많은 기업들이 GPU를 사용하여 AI 모델을 개발하고, 다양한 분야에서 혁신을 이루고 있습니다. 예를 들어, 자율 주행 자동차, 의료 영상 분석, 금융 사기 탐지 등 다양한 분야에서 GPU의 활용이 증가하고 있습니다.
관련 정보: GPU 선택, 나에게 맞는 GPU는? 🤔
GPU를 선택할 때는 다양한 요소를 고려해야 합니다. 예산, 모델 크기, 학습 속도, 메모리 용량 등을 고려하여 자신에게 맞는 GPU를 선택해야 합니다. 마치 옷을 고르는 것처럼, GPU도 자신에게 맞는 것을 선택해야 합니다. 👚
NVIDIA GeForce, NVIDIA Tesla, NVIDIA RTX, AMD Radeon 등 다양한 종류의 GPU가 있으며, 각 GPU는 서로 다른 성능과 가격을 가지고 있습니다. 일반적으로 게임용 GPU는 AI 개발에도 사용할 수 있지만, 더 큰 모델을 학습하거나 더 높은 성능을 원한다면 전문가용 GPU를 사용하는 것이 좋습니다.
| GPU 종류 | 특징 | 추천 대상 |
|---|---|---|
| NVIDIA GeForce | 가성비가 좋음, 게임 및 간단한 AI 개발에 적합 | 예산이 제한적인 학생, 연구원 |
| NVIDIA Tesla | 높은 성능, 대규모 모델 학습에 적합, ECC 메모리 지원으로 안정성 높음 | 대규모 모델 학습, 고성능 컴퓨팅 환경 |
| NVIDIA RTX | Ray Tracing, DLSS 등 고급 기능 지원, 그래픽 작업 및 AI 개발에 적합 | 그래픽 작업, AI 개발, 게임 개발 |
| AMD Radeon | 경쟁력 있는 가격, OpenCL 지원 | OpenCL 기반 개발, 가성비 좋은 GPU를 찾는 사용자 |
컨텐츠 연장: 더 깊이 있는 AI 탐구! 🧠
AI 모델 압축, 효율성을 높여봐요! 💨
모델 압축은 AI 모델의 크기를 줄이고, 추론 속도를 향상시키는 기술입니다. 마치 여행 가방을 효율적으로 싸는 것처럼, 모델 압축은 모델을 더욱 가볍고 효율적으로 만들어줍니다. 💼
모델 압축 기술에는 양자화, 가지치기, 지식 증류 등 다양한 방법이 있습니다. 이러한 기술을 사용하면 모델 크기를 줄이고, 메모리 사용량과 전력 소비를 줄일 수 있습니다.
Transfer Learning, 지식을 나눠봐요! 🤝
Transfer Learning은 이미 학습된 모델의 지식을 다른 모델에 전달하는 기술입니다. 마치 선배의 노하우를 전수받는 것처럼, Transfer Learning은 모델 학습 속도를 높이고, 성능을 향상시킬 수 있습니다. 🧑🏫
Transfer Learning은 이미지 분류, 자연어 처리 등 다양한 분야에서 활용되고 있으며, 특히 데이터가 부족한 경우에 유용합니다.
Auto ML, AI 개발 자동화! ⚙️
Auto ML은 AI 모델 개발 과정을 자동화하는 기술입니다. 마치 자동 조리 기계처럼, Auto ML은 AI 모델 개발을 더욱 쉽고 빠르게 만들어줍니다. 🤖
Auto ML은 데이터 전처리, 모델 선택, 하이퍼파라미터 최적화 등 다양한 작업을 자동화할 수 있으며, AI 전문가가 아니더라도 쉽게 AI 모델을 개발할 수 있도록 도와줍니다.
Edge Computing, AI를 더 가까이! 📍
Edge Computing은 데이터를 클라우드 서버가 아닌, 데이터가 생성되는 장치(Edge)에서 직접 처리하는 기술입니다. 마치 집 앞에서 택배를 받는 것처럼, Edge Computing은 데이터 전송 지연 시간을 줄이고, 보안을 강화할 수 있습니다. 📦
Edge Computing은 자율 주행 자동차, 스마트 팩토리, 스마트 시티 등 다양한 분야에서 활용되고 있으며, 실시간 데이터 처리와 빠른 응답 속도가 필요한 경우에 유용합니다.
Explainable AI, AI를 더 투명하게! 💡
Explainable AI(XAI)는 AI 모델의 의사 결정 과정을 설명할 수 있도록 하는 기술입니다. 마치 속이 보이는 유리 상자처럼, XAI는 AI 모델의 작동 방식을 이해하고, 신뢰도를 높일 수 있습니다. 🧰
XAI는 의료, 금융, 법률 등 다양한 분야에서 중요성이 강조되고 있으며, AI 모델의 공정성, 책임성, 투명성을 확보하는 데 기여합니다.
GPU for AI 글을 마치며… 🎬
GPU for AI에 대한 여정을 함께 해주셔서 감사합니다! 👏 이 글을 통해 GPU 아키텍처, CUDA 프로그래밍, PyTorch/TensorFlow 활용법, 최적화 기술, 확장 학습 방법 등 다양한 지식을 얻으셨기를 바랍니다. 🤗
AI 기술은 끊임없이 발전하고 있으며, GPU는 AI 개발의 핵심 동력으로 계속해서 중요한 역할을 수행할 것입니다. 이 글을 통해 얻은 지식을 바탕으로 AI 개발 능력을 향상시키고, 새로운 가능성을 탐색해보세요! ✨
궁금한 점이나 더 알고 싶은 내용이 있다면 언제든지 댓글로 문의해주세요! 😉 여러분의 AI 여정을 응원합니다! 🙌
GPU for AI 관련 동영상







GPU for AI 관련 상품검색
