



어머, 벌써 케라스 기술을 배우고 이미지 분류 모델까지 만들 수 있다니! 🤩 여러분만 모르고 지나칠까 봐 초조한 마음, 제가 잘 알죠! 😉 지금부터 딱 10분만 투자하면 여러분도 멋진 이미지 분류 모델을 만들 수 있어요. 지금 바로 시작해 볼까요? 🏃♀️
✅ 이 글 하나로 끝내는 케라스 이미지 분류 핵심!
- 케라스 Sequential 모델로 간단하게 이미지 분류 모델 구축하는 방법 마스터!
- MNIST 데이터셋을 활용하여 손쉽게 모델 훈련하고 성능 평가하기!
- 과적합 방지, 데이터 전처리 등 실전 팁으로 모델 성능 극대화하기!
케라스, 너 대체 뭐니? 🤔
케라스(Keras)는 딥러닝 모델을 쉽고 빠르게 만들 수 있도록 도와주는 아주 유용한 도구예요. 🧱 레고 블록처럼 필요한 레이어를 쌓아서 모델을 만들 수 있기 때문에 초보자도 쉽게 접근할 수 있다는 장점이 있죠. 🐍 파이썬 기반이라 사용하기도 편리하고요! 딥러닝을 처음 시작하는 분들에게 케라스는 정말 든든한 친구가 될 거예요. 🤗
이미지 분류, 왜 배워야 할까? 🧐
이미지 분류는 컴퓨터가 이미지를 보고 "이건 고양이!", "저건 강아지!"처럼 자동으로 판단하는 기술이에요. 🐱🐶 이 기술은 우리 생활 곳곳에서 활용되고 있는데요. 예를 들어, 스마트폰 사진첩에서 얼굴 인식 기능이나 스팸 메일 필터링, 자율주행 자동차 등 다양한 분야에서 핵심적인 역할을 하고 있답니다. 🚗✉️ 이미지 분류를 배우면 여러분도 이런 멋진 기술들을 직접 만들 수 있다는 사실! 😎
Sequential 모델, 내 첫 모델로 딱! 👍
케라스에는 다양한 모델을 만들 수 있는 방법이 있지만, 가장 기본적이고 이해하기 쉬운 방법이 바로 Sequential 모델이에요. 🧱 Sequential 모델은 마치 레고 블록을 차곡차곡 쌓듯이 레이어를 순서대로 연결해서 모델을 만드는 방식이죠. 층층이 쌓이는 레이어들을 보면서 딥러닝 모델이 어떻게 작동하는지 직관적으로 이해할 수 있다는 장점이 있어요. 처음 딥러닝을 접하는 분들에게 Sequential 모델은 정말 좋은 시작점이 될 거예요. 😊
MNIST 데이터셋, 친절한 튜터! 🧑🏫
MNIST 데이터셋은 0부터 9까지 손으로 쓴 숫자 이미지들로 이루어진 데이터셋이에요. ✍️ 이 데이터셋은 딥러닝 모델을 훈련하고 테스트하는 데 아주 많이 사용된답니다. 왜냐하면 데이터셋이 깔끔하게 정리되어 있고, 이미지 크기도 작아서 모델 훈련이 빠르거든요. 마치 친절한 튜터처럼 여러분이 딥러닝 모델을 처음 만들 때 옆에서 든든하게 도와줄 거예요. 🤗 MNIST 데이터셋을 가지고 놀면서 딥러닝의 기본을 탄탄하게 다져보세요! 💪
케라스로 Sequential 모델 만들기 (코드와 함께! 💻)
자, 이제 실제로 코드를 작성하면서 케라스 Sequential 모델을 만들어 볼까요? 🚀 걱정 마세요! 아주 쉽고 간단하게 따라 할 수 있도록 제가 옆에서 친절하게 안내해 드릴게요. 😉
1단계: 필요한 라이브러리 불러오기
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Dense, Flatten
import matplotlib.pyplot as plt가장 먼저, 텐서플로우(TensorFlow)와 케라스(Keras) 라이브러리를 불러와야 해요. 그리고 MNIST 데이터셋을 사용하기 위해 keras.datasets에서 mnist를 불러오고, 모델 레이어를 만들기 위해 keras.layers에서 Dense와 Flatten을 불러옵니다. 그림을 그리기 위해 matplotlib.pyplot도 추가로 불러올게요. 🖼️
2단계: MNIST 데이터셋 준비하기
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0MNIST 데이터셋을 불러와서 훈련 데이터와 테스트 데이터로 나눠줍니다. 그리고 이미지 픽셀 값을 0과 1 사이로 정규화해 주는 것도 잊지 마세요! 🧹 이렇게 데이터를 정규화하면 모델이 훨씬 더 빠르고 안정적으로 학습할 수 있답니다.
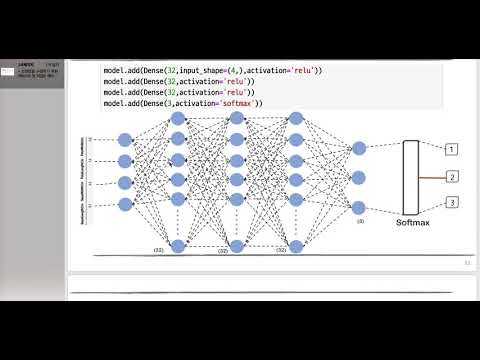
3단계: Sequential 모델 만들기
model = keras.Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])드디어 Sequential 모델을 만들 차례예요! 🧱 가장 먼저 Flatten 레이어를 추가해서 28×28 크기의 이미지 데이터를 784개의 1차원 배열로 만들어줍니다. 그리고 Dense 레이어를 두 개 추가할 건데요. 첫 번째 Dense 레이어는 128개의 뉴런을 가지고 활성화 함수로 ReLU를 사용하고, 두 번째 Dense 레이어는 10개의 뉴런을 가지고 활성화 함수로 Softmax를 사용합니다. Softmax 함수는 각 클래스에 대한 확률값을 출력해 주기 때문에 이미지 분류 문제에 아주 유용하답니다. 💡
4단계: 모델 컴파일하기
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])모델을 컴파일할 때는 옵티마이저(optimizer), 손실 함수(loss function), 그리고 평가 지표(metrics)를 설정해야 해요. 여기서는 옵티마이저로 Adam을, 손실 함수로 sparse_categorical_crossentropy를, 그리고 평가 지표로 정확도(accuracy)를 사용했어요. Adam은 학습 속도를 자동으로 조절해 주는 아주 똑똑한 옵티마이저랍니다. 🤓
5단계: 모델 훈련하기
model.fit(x_train, y_train, epochs=5)이제 모델을 훈련시킬 시간이에요! 🏋️♀️ fit 함수를 사용해서 훈련 데이터와 레이블을 넣어주고, epochs 파라미터를 설정해서 전체 훈련 데이터를 몇 번 반복해서 학습할지 결정합니다. 여기서는 epochs를 5로 설정했어요. 즉, 훈련 데이터를 5번 반복해서 학습한다는 의미랍니다.
6단계: 모델 평가하기
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('nTest accuracy:', test_acc)모델 훈련이 끝났으면 이제 테스트 데이터를 사용해서 모델 성능을 평가해야겠죠? 🧐 evaluate 함수를 사용해서 테스트 데이터와 레이블을 넣어주면 손실 값(loss)과 정확도(accuracy)를 얻을 수 있어요. 테스트 정확도가 높을수록 모델이 새로운 데이터에 대해서도 예측을 잘한다는 의미겠죠? 🎉
과적합, 너는 OUT! 🙅♀️
모델이 훈련 데이터에 너무 익숙해져서 새로운 데이터에 대한 예측 성능이 떨어지는 현상을 과적합(overfitting)이라고 해요. 마치 시험 문제만 달달 외워서 풀고 실제 문제는 못 푸는 학생과 같은 거죠. 😅 과적합을 방지하기 위해서는 다양한 방법들이 있는데요.
- 데이터 양 늘리기: 훈련 데이터를 더 많이 확보하면 모델이 다양한 패턴을 학습할 수 있어서 과적합을 줄일 수 있어요. 🎁
- 규제(Regularization): 모델의 복잡도를 제한하는 방법이에요. L1 규제, L2 규제 등이 있답니다. 🔨
- 드롭아웃(Dropout): 모델의 일부 뉴런을 임의로 제거하면서 학습시키는 방법이에요. 🤪
- 조기 종료(Early Stopping): 검증 데이터에 대한 성능이 더 이상 향상되지 않으면 학습을 중단하는 방법이에요. 🛑
데이터 전처리, 깔끔함이 생명! ✨
데이터 전처리는 모델 훈련 전에 데이터를 정리하고 변환하는 과정을 말해요. 마치 요리하기 전에 재료를 손질하는 것과 같죠. 🥕🧅 데이터 전처리를 제대로 해주면 모델 성능을 훨씬 더 향상시킬 수 있답니다.
- 정규화(Normalization): 데이터 값의 범위를 0과 1 사이로 조정하는 방법이에요.
- 표준화(Standardization): 데이터 값의 분포를 평균이 0이고 표준편차가 1이 되도록 변환하는 방법이에요.
- 결측값 처리(Missing Value Handling): 데이터에 비어있는 값이 있을 경우, 이를 적절한 값으로 채워주거나 해당 데이터를 제거하는 방법이에요.
- 이상치 제거(Outlier Removal): 데이터에서 비정상적으로 큰 값이나 작은 값을 제거하는 방법이에요.
CNN, 이미지 분석 전문가! 🧑💻
합성곱 신경망(Convolutional Neural Network, CNN)은 이미지 분류, 객체 탐지 등 다양한 이미지 관련 작업에서 뛰어난 성능을 보이는 딥러닝 모델이에요. 🖼️ CNN은 이미지의 특징을 추출하는 컨볼루션(convolution) 레이어와 추출된 특징을 요약하는 풀링(pooling) 레이어로 구성되어 있어요. 마치 이미지 분석 전문가처럼 이미지 속에서 중요한 정보들을 쏙쏙 뽑아낸답니다. 🧐
데이터 증강, 마법처럼 데이터 늘리기! 🧙♀️
데이터 증강(Data Augmentation)은 기존의 훈련 데이터를 변형해서 데이터셋의 크기를 늘리는 방법이에요. 마치 마법처럼 데이터를 복제하는 것과 같죠! 🪄 이미지 데이터를 증강할 때는 회전, 확대/축소, 좌우 반전, 상하 반전, 색상 변경 등 다양한 방법들을 사용할 수 있어요. 데이터 증강을 통해 모델의 일반화 성능을 향상시키고 과적합을 방지할 수 있답니다.
전이 학습, 이미 훈련된 모델 활용하기! 🤝
전이 학습(Transfer Learning)은 이미 다른 데이터셋으로 훈련된 모델을 가져와서 내가 풀고 싶은 문제에 맞게 재학습시키는 방법이에요. 마치 베테랑 요리사의 레시피를 참고해서 새로운 요리를 만드는 것과 같죠! 👨🍳 전이 학습을 사용하면 적은 양의 데이터로도 높은 성능을 낼 수 있고, 모델 훈련 시간도 단축할 수 있다는 장점이 있어요.
케라스 모델 저장하고 불러오기 💾
모델을 힘들게 훈련시켰는데, 다음에 또 사용하려면 어떻게 해야 할까요? 🤔 걱정 마세요! 케라스에서는 모델을 저장하고 불러오는 기능을 아주 간단하게 제공하고 있답니다.
모델 저장하기
model.save('my_model.h5')save 함수를 사용해서 모델을 파일로 저장할 수 있어요. 파일 확장자는 보통 .h5를 사용합니다.
모델 불러오기
from tensorflow.keras.models import load_model
model = load_model('my_model.h5')load_model 함수를 사용해서 저장된 모델을 불러올 수 있어요. 이제 언제든지 저장된 모델을 불러와서 사용할 수 있겠죠? 😊
케라스 콜백 함수, 똑똑한 도우미! 🙋♀️
케라스 콜백 함수(Callback)는 모델 훈련 중에 특정 시점에 호출되는 함수예요. 마치 훈련 과정을 도와주는 똑똑한 도우미와 같죠! 🙋♀️ 콜백 함수를 사용하면 모델 훈련을 모니터링하고, 학습률을 조절하고, 과적합을 방지하는 등 다양한 작업들을 자동화할 수 있답니다.
- ModelCheckpoint: 모델의 가중치를 주기적으로 저장해 주는 콜백 함수예요.
- EarlyStopping: 검증 데이터에 대한 성능이 더 이상 향상되지 않으면 학습을 조기 종료시켜 주는 콜백 함수예요.
- ReduceLROnPlateau: 검증 데이터에 대한 성능이 개선되지 않으면 학습률을 낮춰 주는 콜백 함수예요.
- TensorBoard: 훈련 과정을 시각적으로 보여주는 콜백 함수예요.
케라스 튜닝, 숨겨진 성능을 깨워라! 🔑
모델 튜닝(Hyperparameter Tuning)은 모델의 성능을 최적화하기 위해 하이퍼파라미터 값을 조정하는 과정을 말해요. 마치 자물쇠의 비밀번호를 맞춰서 숨겨진 보물을 찾는 것과 같죠! 🔑 하이퍼파라미터는 학습률, 배치 크기, 레이어 수, 뉴런 수 등 모델의 구조와 학습 방식을 결정하는 값들을 의미합니다.
- Grid Search: 하이퍼파라미터 값들을 미리 정해놓고 모든 조합에 대해 모델을 훈련시켜 보는 방법이에요. 촘촘하게 탐색할 수 있지만, 시간이 오래 걸린다는 단점이 있어요.
- Random Search: 하이퍼파라미터 값들을 무작위로 선택해서 모델을 훈련시켜 보는 방법이에요. Grid Search보다 빠르게 탐색할 수 있지만, 최적의 값을 찾을 확률이 낮다는 단점이 있어요.
- Bayesian Optimization: 이전 탐색 결과를 바탕으로 다음에 탐색할 하이퍼파라미터 값을 예측하는 방법이에요. Grid Search와 Random Search보다 효율적으로 최적의 값을 찾을 수 있다는 장점이 있어요.
실전 사례: 케라스로 강아지 vs 고양이 분류하기 🐶🐱

케라스 기술을 이용해서 실제로 강아지와 고양이 이미지를 분류하는 모델을 만들어 볼까요? 🤩 Kaggle에서 제공하는 "Dogs vs. Cats" 데이터셋을 사용하면 아주 쉽게 모델을 만들 수 있답니다. CNN 모델을 사용하고 데이터 증강 기법을 적용하면 꽤 높은 정확도를 얻을 수 있을 거예요. 한번 도전해 보세요! 💪
케라스, 어디까지 발전할까? 🚀
케라스는 딥러닝 분야에서 가장 인기 있는 프레임워크 중 하나로, 앞으로도 꾸준히 발전할 것으로 예상됩니다. 🤗 특히, 케라스는 텐서플로우(TensorFlow)와 통합되면서 더욱 강력해졌는데요. 앞으로는 케라스를 이용해서 더욱 복잡하고 다양한 딥러닝 모델들을 쉽게 만들 수 있을 것으로 기대됩니다.
케라스 기술 글을 마치며… 💖

자, 이렇게 해서 케라스 Sequential 모델로 이미지 분류 모델을 만드는 방법을 함께 알아봤어요. 어때요? 생각보다 어렵지 않죠? 😉 케라스는 딥러닝을 처음 시작하는 분들에게 정말 좋은 도구인 것 같아요. 레고 블록처럼 레이어를 쌓아서 모델을 만드는 재미도 쏠쏠하고요! 😊
이 글을 통해서 여러분이 케라스 기술에 대한 자신감을 얻고, 딥러닝의 세계에 발을 들여놓는 데 도움이 되었으면 좋겠어요. 앞으로도 케라스를 꾸준히 공부하고 활용해서 여러분만의 멋진 딥러닝 모델들을 만들어 보세요! 🚀 궁금한 점이 있다면 언제든지 저에게 물어보시고요. 😉 저는 언제나 여러분을 응원합니다! 🙌
Happy Keras! 💖
케라스 기술 관련 동영상






케라스 기술 관련 상품검색
